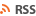검색결과 리스트
작업일지2에 해당되는 글 20건
- 2019.11.02 공일
- 2019.10.16 단어추출하기 KoNLP, 빈도수 높은 단어를 워드클라우드 표현
- 2019.09.25 객체 조회/삭제/저장/불러오기
- 2019.09.20 [제어문] if/else, for문
- 2019.09.18 나만의 함수 만들기!!
- 2019.09.10 [리스트]모든 요소에 일괄 반영
- 2019.09.08 리스트 생성, 요소 접근
- 2019.09.06 데이터 프레임의 구조 변경
- 2019.09.04 데이터 변경
- 2019.08.28 데이터 개요 보기, 데이터 탐색
글
공일
'작업일지2' 카테고리의 다른 글
| 단어추출하기 KoNLP, 빈도수 높은 단어를 워드클라우드 표현 (0) | 2019.10.16 |
|---|---|
| 객체 조회/삭제/저장/불러오기 (0) | 2019.09.25 |
| [제어문] if/else, for문 (0) | 2019.09.20 |
| 나만의 함수 만들기!! (0) | 2019.09.18 |
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
글
단어추출하기 KoNLP, 빈도수 높은 단어를 워드클라우드 표현

코타키나발루를 블로그에 검색한 결과에서 단어만 추출해 그 결과를 확인해보자.

글자 길이가 1이거나 의미없는 단어들을 제거한다.

빈도수(table)를 기준으로 내림차순으로 상위 50개 단어를 추출한다.

추출한 단어들을 wordcloud2 패키지의 wordcloud2 함수를 활용해 워드 클라우드로 표현해보았다.
wordcloud2(data, size, shape)
data: 단어와 빈도수 정보가 포함된 데이터프레임 또는 테이블
size: 글자 크기
shape: 워드 클라우드의 전체 모양(circle, cardioid, diamond, triangle, star 등)


'작업일지2' 카테고리의 다른 글
| 공일 (0) | 2019.11.02 |
|---|---|
| 객체 조회/삭제/저장/불러오기 (0) | 2019.09.25 |
| [제어문] if/else, for문 (0) | 2019.09.20 |
| 나만의 함수 만들기!! (0) | 2019.09.18 |
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
글
객체 조회/삭제/저장/불러오기
R 객체들은 모두 메모리 상에서 처리되므로 갑자기 R이 다운되면 객체들은 모두 사라진다.
따라서 갑자기 오류가 떠서 작업물이 모두 사라질 수도 있다. R에서는 객체를 디스크에 저장하고 다시 불러와 사용할 수 있는 명령어를 제공한다.
-객체 목록 조회: ls()
-객체 삭제: rm(객체, 객체, 객체, ...)
-특정 객체를 파일로 저장: save(객체, 객체, ..., file= "파일명.rdata")
-모든 객체를 파일로 저장: save.image("파일명.rdata")
-파일로부터 객체 불러오기: load("파일명.rdata")


'작업일지2' 카테고리의 다른 글
| 공일 (0) | 2019.11.02 |
|---|---|
| 단어추출하기 KoNLP, 빈도수 높은 단어를 워드클라우드 표현 (0) | 2019.10.16 |
| [제어문] if/else, for문 (0) | 2019.09.20 |
| 나만의 함수 만들기!! (0) | 2019.09.18 |
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
글
[제어문] if/else, for문
if/else 문
if(조건)
{조건이 맞을 때 실행할 구문}
else
{조건에 맞지 않을 때 실행할 구문}&&: AND 조건
||: OR 조건

if/else로 처리하는 구문이 단순한 경우 ifelse함수로 간단히 표현 가능
ifelse(조건, 조건이 맞을 때 실행 구문, 조건에 맞지 않을 때 실행할 구문)
조건이 하나 이상인 경우 else if를 통해 조건을 추가할 수 있고 여러 번 추가 가능
else if(조건){조건 해당 시 수행할 구문}
for문
특정 구문을 반복적으로 수행할 때 for문 사용
for( x in 시작인덱스 : 종료인덱스 ){
반복해서 처리할 구문
}

'작업일지2' 카테고리의 다른 글
| 단어추출하기 KoNLP, 빈도수 높은 단어를 워드클라우드 표현 (0) | 2019.10.16 |
|---|---|
| 객체 조회/삭제/저장/불러오기 (0) | 2019.09.25 |
| 나만의 함수 만들기!! (0) | 2019.09.18 |
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
| 리스트 생성, 요소 접근 (0) | 2019.09.08 |
글
나만의 함수 만들기!!
함수 생성 및 함수의 특징
함수를 생성하는 기본 구조
function( 입력 항목, 입력 항목, ... ) {
함수에서 사용할 구문
return(반환할 객체)
}
만약 return 문을 명시하지 않으면 마지막 문장이 만드는 결과를 반환한다. 이를 활용해 내 간단한 함수인 경우 소스의 간결성을 위해 return 문을 생략하기도 한다.
하지만 복잡한 함수의 경우에는 소스의 이해를 돕기 위해 return 문을 명시하는 것이 좋다.
*주의: 함수 내의 모든 변경은 함수 내에서만 유효하므로 "<-" 연산자를 통해 특정 객체에 반환한 객체를 지정해주어야 한다.

'작업일지2' 카테고리의 다른 글
| 객체 조회/삭제/저장/불러오기 (0) | 2019.09.25 |
|---|---|
| [제어문] if/else, for문 (0) | 2019.09.20 |
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
| 리스트 생성, 요소 접근 (0) | 2019.09.08 |
| 데이터 프레임의 구조 변경 (0) | 2019.09.06 |
글
[리스트]모든 요소에 일괄 반영
lapply, sapply
lapply(리스트, 적용할 함수): 리스트로 반환
sapply(리스트, 적용할 함수): 함수 결괏값이 한 개인 경우 벡터로 반환. 함수 결괏값이 같은 길이의 벡터라면 행렬로 반환. 그 밖의 경우에는 리스트로 반환한다.

'작업일지2' 카테고리의 다른 글
| [제어문] if/else, for문 (0) | 2019.09.20 |
|---|---|
| 나만의 함수 만들기!! (0) | 2019.09.18 |
| 리스트 생성, 요소 접근 (0) | 2019.09.08 |
| 데이터 프레임의 구조 변경 (0) | 2019.09.06 |
| 데이터 변경 (0) | 2019.09.04 |
글
리스트 생성, 요소 접근
리스트 생성
list 함수로 리스트를 생성한다.
list( 객체, 객체, 객체, ... )
> vt_1 <- c(1,2,3,4,5)
> vt_2 <- c(T, F, T, T, F, T)
> df_1 <- data.frame(name = c("Alice", "James", "Merry"), age = c(23, 41, 19))
> var_list <- list(vt_1, vt_2, df_1, sum)
> var_list
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] TRUE FALSE TRUE TRUE FALSE TRUE
[[3]]
name age
1 Alice 23
2 James 41
3 Merry 19
[[4]]
function (..., na.rm = FALSE) .Primitive("sum")더 깔끔하게 요소에 이름을 지정할 수도 있다.
> var_list <- list( v1 = vt_1, v2 = vt_2, df1 = df_1, function1 = sum)
> var_list
$`v1`
[1] 1 2 3 4 5
$v2
[1] TRUE FALSE TRUE TRUE FALSE TRUE
$df1
name age
1 Alice 23
2 James 41
3 Merry 19
$function1
function (..., na.rm = FALSE) .Primitive("sum")
요소 접근하기
리스트 내 요소는 순서 또는 요소명을 통해 접근할 수 있다.
*주의: 요소에 접근하려면 []가 아닌 [[]]를 통해 접근해야 한다.
> var_list[1]
$`v1`
[1] 1 2 3 4 5
> str(var_list[1])
List of 1
$ v1: num [1:5] 1 2 3 4 5
> var_list[[1]]
[1] 1 2 3 4 5
> str(var_list[[1]])
num [1:5] 1 2 3 4 5요소에 접근하는 다양한 방법
> names(var_list)
[1] "v1" "v2" "df1" "function1"
> var_list[[2]]
[1] TRUE FALSE TRUE TRUE FALSE TRUE
> var_list[["v2"]]
[1] TRUE FALSE TRUE TRUE FALSE TRUE
> var_list$v2
[1] TRUE FALSE TRUE TRUE FALSE TRUE
'작업일지2' 카테고리의 다른 글
| 나만의 함수 만들기!! (0) | 2019.09.18 |
|---|---|
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
| 데이터 프레임의 구조 변경 (0) | 2019.09.06 |
| 데이터 변경 (0) | 2019.09.04 |
| 데이터 개요 보기, 데이터 탐색 (0) | 2019.08.28 |
글
데이터 프레임의 구조 변경
데이터프레임의 열을 추가/삭제/수정하는 방법
열 추가
'<-' 연산자로 열을 추가할 수 있다.
데이터프레임명$새로만들 열 이름 <- 추가할 데이터 벡터
열 삭제
열에 NULL 값을 지정해 열을 삭제할 수 있다.(소문자 null은 적용x)
데이터프레임명$삭제할 열 이름 <- NULL

여러 개의 열을 삭제할 때는 삭제할 칼럼을 선택한 후 list(NULL)
데이터프레임명[ , 칼럼인덱스벡터] <- list(NULL)

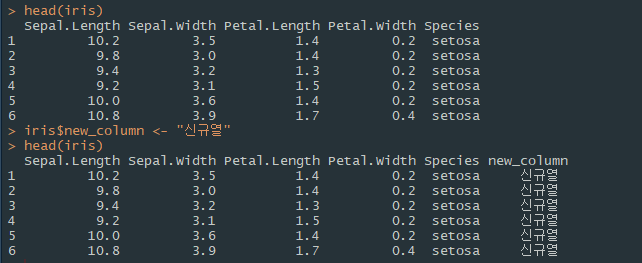
열 이름과 데이터 타입 변경
colnames 함수를 이용해 열 이름을 조회하거나 수정할 수 있다.
colnames(데이터프레임명)
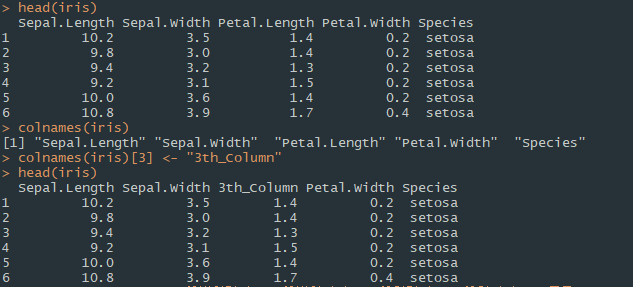
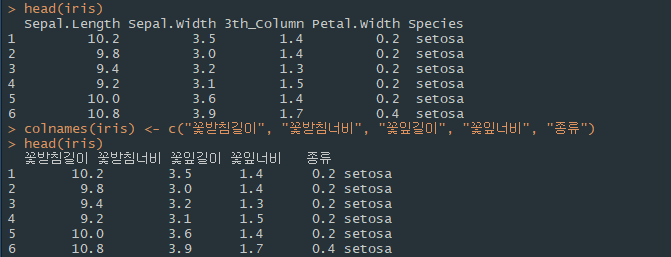
데이터프레임 간의 결합
-열 기준 결합:
단순병합인 경우 cbind 함수 사용
cbind( 데이터프레임1, 데이터프레임2)

데이터프레임 간의 열들의 순서가 맞지 않아도 특정 열을 기준으로 같은 행들을 연결하여 결합할 때는 merge함수 사용
merge( 데이터프레임1, 데이터프레임2, by = 결합기준 열 벡터 )

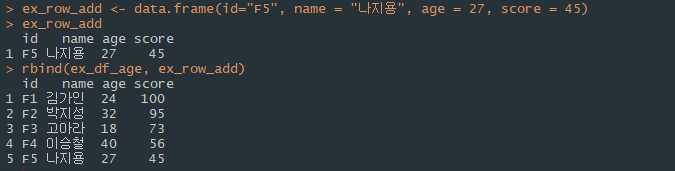
-행 기준 결합:
rbind( 데이터프레임1, 데이터프레임2 )
*주의: 두 데이터프레임 간의 열의 이름과 개수가 같아야 한다.
'작업일지2' 카테고리의 다른 글
| [리스트]모든 요소에 일괄 반영 (0) | 2019.09.10 |
|---|---|
| 리스트 생성, 요소 접근 (0) | 2019.09.08 |
| 데이터 변경 (0) | 2019.09.04 |
| 데이터 개요 보기, 데이터 탐색 (0) | 2019.08.28 |
| 데이터프레임, 데이터 접근 (0) | 2019.08.25 |
글
edit 함수 활용
데이터 크기가 크지 않으면 edit 함수를 통해 간단히 수정할 수 있다. edit 함수는 입력한 데이터프레임을 직접 수정해주지 않으므로 edit함수의 결과를 별도의 객체에 지정해야 한다.


열 이름을 변경하거나 새로운 열을 추가할 수도 있다.
직접 변경하기
위에서 본 edit 함수는 데이터가 많거나 특정 조건의 데이터에 일괄적으로 수식을 적용해 변경하기는 힘들다. 이 경우, 변경할 데이터를 선택한 후 직접 값을 변경할 수 있다.

'작업일지2' 카테고리의 다른 글
| 리스트 생성, 요소 접근 (0) | 2019.09.08 |
|---|---|
| 데이터 프레임의 구조 변경 (0) | 2019.09.06 |
| 데이터 개요 보기, 데이터 탐색 (0) | 2019.08.28 |
| 데이터프레임, 데이터 접근 (0) | 2019.08.25 |
| 벡터 간의 연산 (0) | 2019.08.23 |
글
데이터 개요 보기, 데이터 탐색
데이터 개요 보기
R에는 기본적으로 제공되는 iris라는 데이터 셋이 있다.
iris는 150개의 행, 5개열로 구성되어 있고, 5개 열의 속성과 일부 데이터 값을 확인할 수 있다.


데이터프레임의 총 행 수는 nrow, 총 열 수는 ncol 함수로 알 수 있다.

*데이터프레임의 데이터가 매우 많을 때는 창에 출력하는 데에만 엄청난 시간이 걸려서 head함수와 tail함수를 이용해 앞뒤 일부만 출력 가능
head( 데이터프레임명, 보고 싶은 행 수) 행 수 입력 안하면 기본적으로 6행 출력
tail( 데이터프레임명, 보고 싶은 행 수) 행 수 입력 안하면 기본적으로 6행 출력

summary 함수를 통해 각 열의 데이터에 대한 요약 정보를 확인 가능
summary( 데이터프레임명 )

숫자 데이터의 경우 Min최솟값, 1st Qu1사분위 수, Median중간값, Mean평균, 3rd Qu3분위 수, Max최댓값을 보여줌.
팩터의 경우 각 범주 당 몇 개가 존재하는지 집계함.
별도의 통계 함수로도 특정 값을 산출할 수 있다.

View 함수: 데이터프레임 표 형식으로 조회하고 정렬 및 조건 검색 가능
Filter 기능을 이용해 원하는 조건에 부합하는 데이터만 볼 수 있다.

subset 함수로 조건 검색
다양한 조건들을 조합해 큰 데이터를 분석해야 할 때는 View 보다 subset 등 조건 검색을 지원하는 함수나 논리벡터를 활용해 데이터를 확인한다.
subset( 데이터프레임명, 찾고자 하는 조건, 조회하고 싶은 열(입력안하면 전체 조회))
A%in% ( c(2,4,5)) : A는 2,4,5 중 하나인 것

+)함수 호출하기
1. 입력 항목명을 지정하지 않고 입력 객체를 순서대로 입력

2. 입력 항목명을 지정해 입력 - 순서를 지키지 않아도 된다!!

attach와 detach 함수
[]를 사용해 데이터프레임에서 조건 검색을 할 때는 subset 함수와 달리 열 이름 앞에 항상 데이터프레임명도 명시해주어야 하기 때문에 가독성이 떨어지고 코드가 너무 길어질 수 있다. attach 함수는 R이 객체를 찾는 경로를 추가해 주는 함수로서 데이터프레임을 추가하면 R은 우선적으로 등록한 데이터프레임 내부에서 객체를 찾아준다. 따라서 열 이름 앞에 데이터프레임명을 명시해주지 않아도 된다. attach 함수의 설정 내역을 해제할 때는 detach 함수를 사용한다.
attach(데이터프레임명)
detach(데이터 프레임명)
*주의사항
[] 연산자로 데이터프레임을 조건 검색한 결과가 한 개의 열이면 데이터프레임이 아닌 벡터로 반환한다. 벡터로의 반환은 프로그램 내의 오류를 발생시키기도 한다. 데이터프레임 형태를 유지하여 조회하고 싶으면 drop = FALSE 옵션을 사용한다.
정렬
[] 연산자를 사용해 벡터 요소의 순서를 변경해 행이 출력되는 순서를 바꿀 수 있다.

order 함수는 입력받은 데이터를 정렬시켜 값이 아닌 위치 벡터를 반환한다.
order( x, decreasing, na.last)
x: 정렬할 벡터. 만약 정렬기준이 여러 개면 연속으로 입력
decreasing: TRUE면 내림차순, FALSE면 오름차순
na.last: 정렬 시 유효하지 않은 값 위치를 지정. TRUE면 맨 끝에, FALSE면 맨 앞에, NA면 정렬 시 NA값 제거

*sort 함수는 order 함수처럼 정렬된 순서를 나타내지만 위치벡터를 반환하는 order 함수와 달리 sort 함수는 벡터값 자체를 반환한다.
그룹 지어보기
aggregrate 함수: 특정 열을 기준으로 그룹을 지어 집계할 때 사용
aggregate( formula, data, FUN)
formula: 집계 기준을 표현한 식 집계할 열~집계 기준열
data: 집계할 데이터프레임
FUN: 집계할 함수
aggregate 함수의 입력항목 중 formula는 "~"를 기준으로 왼쪽은 집계할 열, 오른쪽은 집계 기준열을 나타낸다. 집계할 열이 여러 개면 cbind 함수로 연결하고 집계 기준열이 여러 개면 "+"기호로 연결한다.
cbind(집계할 열1, 집계할 열2, 집계할 열3) ~ 집계 기준열 + 집계 기준열2
만약 데이터프레임에서 집계 기준이 되는 열을 제외한 나머지 열 모두를 집계하는 것이면 해당 열들을 모두 나열하는 대신 "."기호로 대체할 수 있다.
. ~ 집계 기준열1 + 집계 기준열2

'작업일지2' 카테고리의 다른 글
| 데이터 프레임의 구조 변경 (0) | 2019.09.06 |
|---|---|
| 데이터 변경 (0) | 2019.09.04 |
| 데이터프레임, 데이터 접근 (0) | 2019.08.25 |
| 벡터 간의 연산 (0) | 2019.08.23 |
| 벡터 요소 수정/추가/삭제 (0) | 2019.08.16 |